

Vereinfacht beschrieben ist der Zweck von Data Governance die Verwaltung und Organisation des Daten-Lebenszyklus.
Die damit verbundenen Handlungsfelder lassen sich in einem Data Governance Framework zusammenfassen:
Es werden Rollen definiert und mit Personen besetzt, um die dazugehörigen Aufgaben für die Data Governance zu erledigen.
mehr →Data Governance steuert die mit den Daten verbundenen Prozesse und stellt die Basis für die Arbeit der entsprechenden Rollen dar.
mehr →Daten sind einer Reihe von internen und externen Regelwerke unterworfen, zB. der DSGVO oder spezifische Security-Richtlinien.
mehr →Die Umsetzung von Rollen, Prozessen und Regelwerken werden durch den Einsatz von Technologien und Tools unterstützt.
mehr →Teil 1: Dienstag, 1. Februar 2022 | 10:00 - 11:00 Uhr
Einführung Data Governance
Bernhard Engleder und Reinhard Kronsteiner
Teil 2: Donnerstag, 3. Februar 2022 | 10:00 - 11:00 Uhr
Data Governance mit Azure Purview
Bernhard Engleder und Wolfgang Straßer


Im Rahmen von Data Governance werden zahlreiche Rollen definiert. Dabei sind die Data Stewards und Data Governance Manager die wesentlichsten.
Je nach Umfang der Data Governance Initiative ist es sinnvoll, noch weitere Rollen ins Team mit aufzunehmen und die Rollenlandschaft weiter zu skalieren.
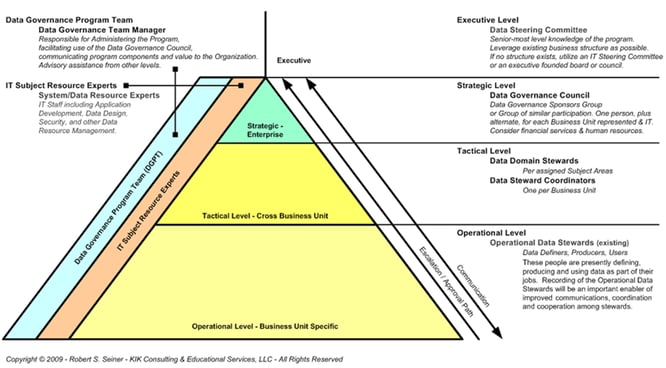
Die Rollenpyramide von Robert Seiner zeigt eine sehr ausgeprägte Struktur der Rollen, wie sie in großen Organisationen durchaus angebracht ist. Die Rollen werden dabei dem operativen, taktischen oder strategischen Level zugeordnet. Derart umfangreiche Organisationsstrukturen bedürfen wiederum eigener interner Steuermechanismen mit einem Data Governance Programm Team zur administrativen Unterstützung.
Es werden Rollen definiert und mit Personen besetzt.
Im Rahmen von Data Governance werden einige Rollen definiert. Die beiden wichtigsten Rollen in Data Governance Initiativen sind der Data Governance Manager und die Data Stewards.
Die weiteren Rollen werden je nach Umfang der Data Governance Initiative erforderlich.
Der Data Governance Manager ist der operativ Verantwortliche für das Data Governance Programm. Er steuert die Data Governance Initiative und garantiert deren Ausrichtung an den vereinbarten Visionen und Zielen.
Unter Data Stewards versteht man Personen, die direkt für Erzeugung, Änderung oder Nutzung von bestimmten Daten verantwortlich sind. Sie sind die Datenkümmerer und sorgen für deren Verfügbarkeit und dafür dass die Daten auch den Qualitätsanforderungen entsprechen.
Diese sind über alle Ebenen wichtige Wissensträger.
Data Domain Stewards sind für eine Data Domain verantwortlich. Diese sind entweder nach Themenbereichen (z.B. Kundendaten) oder nach System-Ebenen (z.B. operative Systeme vs. DWH-Systeme) geclustert.
Data Domain Stewards sind geschäftsbereichsübergreifend tätig.
Data Steward Koordinatoren sind pro Geschäftsbereich für die Informationsverteilung an die operative Ebene verantwortlich.
Dies ist Entscheidendes Gremium auf strategischer Ebene
Die Herangehensweise bei Kundenprojekten orientiert sich in vielen Fällen nur bedingt an der vorgeschlagenen Rollenpyramide von Seiner. Jegliche Erweiterung der Aufbauorganisation muss mit großem Bedacht auf die bestehenden Strukturen erfolgen. In vielen Unternehmen sind folgende Rollen besetzt, die sinnvollerweise in Data Governance Initiativen eingebunden werden sollten:
BI Analysten sind vor allem auf operativer oder taktischer Ebene eingebunden. Ihre Aufgaben sind die Spezifizierung und Umsetzung von Reportanforderungen für die jeweils verantwortlichen Themenbereiche.
Sie sind Ansprechpartner für die Anwender
und Key User bei Fragen zu Berichten
(sowohl inhaltlich als auch technisch) und fungieren sie als Schnittstelle zwischen Anwender / Key User und IT Entwickler im Reporting Umfeld .
In der Data Governance Initiative müssen diese sicherstellen, dass die festgelegten Prozesse den Vorgaben entsprechend ausgeführt, gesteuert und optimiert werden.
Zu ihren Aufgaben zählt die Abstimmung von Anforderungen im IT-Anforderungsprozess.
Außerdem steuern sie wertvolles Wissen über die Struktur der Vorsystemdaten bei und sind verantwortlich für die Weiterentwicklung des Vorsystems (Change Prozesse).
Das Wissen über die Struktur der Daten liegt oftmals weniger im Fachbereich selbst, sondern eher bei den BI Analysten. Der Beitrag des Fachbereichs zum Datenqualitätsmanagement ist meist durch die Ressourcenverfügbarkeit limitiert.
Externe Dienstleister unterstützen bei der Anwendungsentwicklung und verfügen über Wissen zu Implementierungsdetails. Auch bei der Datenbereitstellung können diese unterstützen und liefern Support bei Änderungen der Daten.
Die hier exemplarisch genannten Rollen wirken bei unseren Kundenprojekten an Data Governance Initiativen mit. Zu beachten ist, dass die Aufgaben auf Entscheidungsebene (Data Governance Manager oder Council), auf Verwaltungsebene (Data Steward Coordinator, Programm Team) und auf operativer Ebene (vor allem Data Stewards, Datenqualitätsmanager) abgedeckt werden bzw. von der Ressourcenkapazität abgedeckt werden können.
Ein Ziel unserer Workshops ist es, die Rollenverteilung gemeinsam mit unseren Kunden herauszuarbeiten und so etwaige Engpässe (bei Kapazitäten oder nicht abgedeckten Aufgaben) aufzeigen zu können. Engpässe können oft entweder durch Schärfung der Rollen oder aber auch durch effizienten Werkzeugeinsatz kompensiert werden.
Die Datenlandschaft in Unternehmen ist in der Regel sehr umfangreich. Unzählige Tabellen aus ERP Systemen, CRM Systemen, der Finanzbuchhaltung, Produktion etc. werden in täglichen operativen Prozessen verwendet. Nicht nur das Volumen dieser Daten erreicht hohe Ausmaße, sondern auch deren Komplexität, vor allem durch den steigenden Bedarf an Anpassungen der jeweiligen Basis Lösungen.
Selbst wenn man sich nur auf jene Daten beschränkt, die essentiell für das Berichtswesen und Analysen sind, haben wir es mit einer schwer handhabbaren Menge an Tabellen, Dateien und Services zu tun, die im Rahmen der Data Governance gesteuert werden sollen. Ab einer gewissen Unternehmensgröße und der damit einhergehenden Systemkomplexität ist es für einzelne Wissensträger nur noch bedingt zumutbar, hier den kompletten Überblick zu bewahren und die Verantwortung für die Governance über all diese Systeme und den damit produzierten Daten zu übernehmen.
Als Ordnungsbegriff haben sich an dieser Stelle sogenannte Data Domains etabliert.
Wir versammeln unter einer Data Domain jene Daten, die entweder einem gemeinsamen Zweck dienen oder einer homogenen Quelle entspringen.
Die Bildung von Data Domains erfolgt meist auf Basis der eingebundenen Vorsysteme. Beispielsweise Buchhaltungsdaten als eine Domäne und Produktionsdaten als eine weitere. Ausgehend von meist bereits etablierten Rollen im Unternehmen, wie zum Beispiel Application Owner für die jeweiligen Kernsysteme, können aus dieser Organisation auch die Rollen im Data Governance beschickt werden. Hier ist das Wissen (notwendigerweise) in den Organisationen meist ohnehin sehr ausgeprägt.
Einige Datenbereiche haben jedoch eine Reihe von Vorsystemen und auch fachliche Anwendungsbereiche, auf die sie einwirken. So sind Kundendaten zum Beispiel sowohl in Finanzbuchhaltungs-Anwendungen ebenso relevant, wie in vertriebsunterstützenden Systemen (z.B. CRM). Der Unterschied liegt jedoch in meist differierenden Anforderungen an die Daten in deren Umfang und Qualität. Auch aus dieser "Daten-Subjekt" bezogenen Sicht können Data Domains gebildet werden. Dies bringt insofern großen Nutzen, da der Fokus der Steuerungsaufgaben erstens fachlich über die Verwendung der Daten getrieben ist und großes Potential in den systemübergreifenden Perspektiven der Daten gehoben werden kann (Vermeidung von Redundanzen, Klärung von Synchronisationsmechanismen etc.).
Diese Einordnung dient der Skalierung der Data Governance Initiativen, um die dazugehörigen Rollen, wie zum Beispiel die bereits erwähnten Data Domain Stewards entsprechend mit Wissensträgern besetzen zu können.
Einige Abteilungen müssen in Data Governance Initiativen partnerschaftlich eingebunden werden. Dabei handelt es sich nicht um klassische Einbindung als Rollen im Data Governance Konstrukt, sondern diese organisatorischen Einheiten leisten aufgrund ihrer definierten Aufgabe im Unternehmen einen wesentlichen Beitrag für die Data Governance Initiative im Rahmen "ihrer täglichen Arbeit".
Beispiele für solche Partner im Datagovernance Programm sind:
Mitglieder aus diesen Organisationseinheiten sind in vielen Initiativen notwendig, um Data Governance erfolgreich einleiten zu können und profitieren aber auch ihrerseits in der Regel von diesen. Deren aktueller Beitrag zur Governance in ihrem jeweiligen Bereich muss nicht im Rahmen der Data Governance Initiative repliziert werden. Existierende Zuständigkeiten können jedoch im Sinne eines "minimal invasiven Data Governance Ansatzes" eingebunden werden.
Ein gute Beispiel für eine partnerschaftliche Einbindung sind IT Abteilungen. Sie müssen nicht dezidiert steuernd oder operativ im Rahmen einer klassischen Rolle zur Data Governance beitragen, sind aber üblicherweise stark in die technische Umsetzung und den Betrieb von unterstützenden Lösungen eingebunden. Die IT-bezogenen Aufgaben sind meist durch Linien oder Projektorganisation abgedeckt.
Ebenso werden Beratungsleistung die Daten betreffend aus der Linienorganisation abgedeckt. Ein Beispiel dafür können rechtliche Belange zur Speicherung und Verwendung von z.B. Mitarbeiterdaten sein. Die für die Governance notwendigen Informationen werden auch im operativen Geschäft unabhängig der Data Governance Initiative benötigt
Diese Datagovernance Partner sind jedoch nicht als eigene Gruppe in diesem Kontext zu sehen, sondern werden je nach Bedarf in die einzelnen Prozesse (und deren Gestaltung) eingebunden.
Der wohl wichtigste Prozess im Data Governance ist das Data Quality Monitoring.
Meistens poppt das Thema Datenqualität bei der Anpassung oder Entwicklung von Berichten auf. Werden Daten aus einer "neuen" Perspektive betrachtet, zeigt sich oft, dass deren Qualität dieser neuen Betrachtung nicht vollständig standhalten. Natürlich muss man fairerweise erwähnen, dass eine perfekte Datenqualität meist ein frommer Wunsch ist, jedoch eine zumindest ausreichende Datenqualität sollte permanent gewährleistet werden können.
Im Rahmen von Data Governance gilt es zu vermeiden, dass mäßige Datenqualität erst im veröffentlichten Bericht zum Vorschein kommt. Idealerweise ist die Qualität der Daten bereits vorher bekannt und wird anhand eines klar definierten Regelwerks kontinuierlich geprüft und gemessen. Die Definition des Qualitätsanspruchs an die Daten muss schon ein Teil der Anforderung sein.
Data Quality Monitoring hat mindestens zwei Ausgangspunkte:
Beide Ausgangspunkte müssen zur Anpassung jenes Regelwerkes führen, dem die Daten im Rahmen von ETL Prozessen unterworfen sind. Bei jeder Aktualisierung der Daten für das Berichtswesen kann festgestellt werden, ob den Anforderungen an die Daten genüge getan wird. Im Rahmen der Aktualisierung durchlaufen die Daten eine Reihe von Prüfschritten. Welche diese sind, wird zuerst im Rahmen der Anforderungsdefinition festgelegt. Ein Beispiel dafür wäre, dass kein Angebot ohne vorhandene Kundennummer im Bericht aufscheinen darf.
Werden Fehler im Bericht eingemeldet, kann dies dazu führen, dass die Liste der Prüfregeln angepasst werden muss. Zum Beispiel gibt es möglicherweise "wichtige" Angebote, die mitgezählt werden müssen, obwohl hierzu kein Kunde im Kundenstamm zu finden ist.
Für die Einhaltung dieser Regeln (und die Bearbeitung der Daten bei Regelverletzungen) ist aus Data Governance Sicht im ersten Schritt der Data Steward zuständig. Er muss eine Verbesserung der Daten einleiten oder eine Bearbeitung der Transformationsprozesse veranlassen, zum Beispiel Fallback-Stammdatensätze, die für die genannten Fälle verwendet werden können.
Technisch kann das Datenqualitätsmonitoring in unterschiedlicher Intensität betrieben werden. Es gibt eine Reihe von speziellen Werkzeugen, vor allem im Bereich des Stammdaten-Managements, die auch die kontinuierliche Anwendung von Regelwerken unterstützen. Wir empfehlen einen klaren Prozess für das Issue Tracking, um eine Überführung in die Datenqualitätsregelwerke zu gewährleisten.
Aus BI- und Datawarehouse-Sicht können aber auch schon einfache Datenqualitätsreports (Listen mit Abweichungen von Regelwerk) eine einfache Lösung darstellen. Wichtig dabei bleibt, dass die gemeldeten Regelverletzungen auch bearbeitet werden. Nur weil bekannt ist, dass Daten falsch sind, macht es das nicht zu besseren Daten! Aber man kann in Analysen darauf Rücksicht nehmen, beispielsweise durch das Ausgrenzen "zweifelhafter" Datensätze.
Ein Werkzeug, um sich der unternehmenseigenen Datenlandschaft zu nähern, diese besser zu verstehen und zu verwalten, ist ein Data Cataloging Tool.
Mit Azure Purview wurde Ende letzten Jahres von Microsoft ein Werkzeug veröffentlicht, mit welchem eine "Inventur" der Datenlandschaft, eine Klassifizierung von Dateninhalten und eine Übersicht über die im Unternehmen (zwischen den Systemen) vorhandenen Datenflüssen ermöglicht.
Was Purview ist und wie es funktioniert, zeigt Ihnen Wolfgang Straßer in diesen zwei (englischen) Videos. Viel Spaß dabei!
Mit den in Purview enthaltenen Konnektoren ist es möglich, Verbindungen zu Dateninseln im Unternehmen zu definieren. Der Begriff eines Scans fasst im nächsten Schritt den Scope einer Inventur, die berücksichtigen Klassifikationsregeln und die Frequenz der Scans zusammen.
Purview erstellt im nächsten Schritt eine Datenlandkarte - die Data Map - in welcher die einzelnen Data Assets (Tabellen, Dateien) und deren Zusammenhänge katalogisiert werden.
Mit der webbasierten Oberfläche dem Purview Studio können Data Stewards mit dem erstellten Datennetzwerk arbeiten, nach klassifizierten Datenelementen suchen und deren Zusammenhänge analysieren.
# 1
You heard about Data Governance? You are searching for tool to get an overview about your company's data landscape? In this series, I would like to introduce you to Azure Purview, the data governance and cataloguing solution of Microsoft.
# 2
What are the pieces that put Azure Purview together? In this video I am talking about the Azure Purview architecture, the flow of data and what pieces, concepts and technologies put Azure Purview together.
In einem Data Catalog werden die Bestandteile der Datenlandschaft katalogisiert, klassifiziert, in Relation zu einander gesetzt und über eine der Hauptanwendung des Katalogs - der Suche - den Datenverwendern im Unternehmen zur Verfügung gestellt.
Neben den bestehenden Systemen wie z.B. eine Datenbank werden auch die Strukturen darin - wie z.B. Tabellen und deren Spalten - und die Zusammenhänge der Datenflüsse katalogisiert. Es werden auch die Datenschnittstellen, die zwischen einer Datenbank und einem Data Lake existieren, definiert.
Weiters geht es um die Klassifikation der Daten. Welche Elemente sind im Datenkatalog oder in der einzelnen Tabelle enthalten, wie zum Beispiel eine E-Mail-Adresse. Neben den technischen Strukturen sind im Daten Katalog auch die Verantwortlichkeiten definiert.
Wie kommen die Informationen in den Datenkatalog?
Der Datenkatalog ist also die zentrale Komponente zur Erfassung der Datenlandschaft. Die Inhalte gliedern sich in folgende Bereiche:
Es gelangen folgende Konzepte zum Einsatz:
Wie kommen die Inhalte in den Datenkatalog?
Um den Datenkatalog mit Leben zu befüllen, sind in Azure Purview Datenquellen vorhanden. Diese stellen die Funktionalität zur Verfügung, die technische Inventur der Datenquelle durchzuführen. In diesem Schritt werden (im Beispiel einer Azure SQL Datenbank), die Schema, die Tabellen, die Spalten in diesen Tabellen sowie deren Eigenschaften wir Datentypen etc. eingelesen und verarbeitet.
Im nächsten Schritt können mit Purview automatisierte Datenklassifikation vorgenommen werden. Purview analysiert in diesem Schritt die Datenquellen anhand vordefinierter Klassifikationsregeln (z.B. einem regulären Ausdruck) um u.a. Telefonnummern oder Emailadressen zu erkennen und diesen Elementen eine entsprechende Klassifikation zuzuweisen. Neben den über 200 systemeigenen Klassifikationsregeln können auch eigene Regeln und Klassifikationen erstellt werden.
Im nächsten Schritt kombiniert Purview die gesammelten Informationen in die Data Map - das zentrale Netzwerk an Dateninformationen.
In this video I show you how the Azure Purview Data Map is structured, how Collections are a part of this story and how you can register sources to connect to source systems.
We configured a source in Azure Purview but now we want the metadata to be scanned and imported into the Data Map... What we need to create is a Scan Definition and that's the content of this quickstart episode.
We've configured sources in Azure Purview and added, configured and ran scans to import the technical metadata plus classifications to the data assets. In this video, we will browse through the available data assets in the Azure Purview data map, see how classifications are applied and edit the properties of a data assets. To get more insights about the data catalog content, we'll explore the filtering and browsing experience in Purview studio.
Unter Data Lineage versteht man das nachvollziehbare Aufzeichnen des Weges der Daten
Wozu braucht man das? Sicher sind Ihnen Anfragen wie folgende bekannt:
Diese Fragen können mit Hilfe möglichst konsequenter Data - Lineage adressiert werden. Unter Lineage (ein Begriff aus der Ethnologie) versteht man eine gemeinsame Abstammung oder auch den Familien-Stammbaum. Legt man den Begriff der Lineage auf das Datenumfeld um, so versteht man das nachvollziehbare Aufzeichnen des Weges der Daten.
In erster Linie handelt es sich dabei um eine zu pflegende Dokumentation. Diese kann jedoch (entsprechende Technologien vorausgesetzt) auch automatisiert oder wenigstens teilautomatisiert erfolgen. Mit Azure Purview ist es möglich, automatisiert diese Lineage-Information aus den Datentransformationssystemen wie z.B. Azure Data Factory in die Datenlandkarte zu übernehmen. Weiters hat dieser automatisierte Ansatz den Vorteil, dass die Dokumentation mit jeder Änderung der Pipeline in der Data Factory auch in der aktuellsten Version in Azure Purview veröffentlicht wird.
Weitere Informationen finden Sie auch unter diesem Link: https://learn.g2.com/data-lineage
Ein Datenkatalog lebt durch die gute Integration mit vielen Systemen, um die Strukturen, Datenklassifikationen und Zusammenhänge zwischen den Systemen zu vereinen.
In Azure Purview steht bereits jetzt eine Vielzahl an Schnittstellen zur Verfügung - die Liste an native unterstützten Systemen wird von Monat zu Monat länger.
Eine sehr wichtige Schnittstelle stellt die Power BI Integration in Azure Purview dar. Mit dieser Integration von Power BI in die Azure Purview Data Map besteht nun die Möglichkeit, die Datalineage (Herkunft) von der Datenquelle über die Aufbereitungen, das Power BI Datenmodell bis zu den Power BI Reports und Dashboards nachzuvollziehen.
Mit der nun verfügbaren Metadatenschnitstelle ist es möglich, die Inhalte von Power BI Datasets in die Purview Data Map zu überführen und Power BI als ein Teil der gesamten Datenherkunft zu analysieren.
Falls Sie diese Integration live sehen wollen, gibt es dazu ein kurzes Video!
With August 2021, more and enhanced metadata from Power BI is integrated into the Azure Purview data map. Let's see it in the demo how it works and what you need to configure beforehand that it works.
Neben den technischen Details im Datenkatalog ist eine für die Anwender in den Fachabteilungen verständliche Definition zwingend notwendig. In diesem Zusammenhang spricht man vom Business Glossary.
Die Idee hinter einem Business Glossary ist einfach definiert - in einem Unternehmen sollten wir alle vom selben sprechen! Nehmen wir nur die Definition von Kennzahlen wie dem Umsatz, dem Deckungsbeitrag 1 oder anderen Berechnungen.
Hier ist es wichtig, dass diese Informationen gleich definiert sind, aber auch definiert ist wo diese Informationen in der Datenlandschaft zur Verfügung stehen.
Im Business Glossary können diese Definitionen in einem einheitlichen Schema und einer Struktur abgelegt werden und im nächsten Schritt den Data Assets im Katalog zugewiesen werden. So wird mit dieser Aktion der Schritt von der technischen Inventur (den technischen Elementnamen) in Richtung einer geschäftsorientierten Klassifikation vorgenommen.
Wie das Business Glossary in Azure Purview definiert und verwendet wird zeigen wir Ihnen in diesem kurzen Video!
Lorem ipsum dolor sit amet, consectetur adipiscing elit
Azure Purview allows you to automatically classify your assets based on the data stored in them. In addition, Business Glossary Terms can be applied to data assets.

