Ein Blick in die Vergangenheit von Microsoft Analytics...
Erinnern Sie sich noch an die guten alten Zeiten, als es "nur" SQL Server DB-Engine, Integration Services, Analysis Services und Reporting Services gab und Ihre Data Warehouse-Lösung fertig war?
Dann kam die Cloud mit einer riesigen Auswahl an Diensten zum Aufbau von Analyselösungen - Azure Data Factory, Azure Data Lake Storage, Azure SQL Database und Power BI. Es gab verschiedene Möglichkeiten, diese Puzzlestücke zu kombinieren. Und wenn wir auf die Kostenschätzungsgespräche mit den Kunden zurückblicken... Das war keine leichte Aufgabe.
2019 wurde die Preview von Azure Synapse Analytics veröffentlicht. Mir gefiel die Idee einer integrierten Analyselösung, die verschiedene Arten der Datenspeicherung (Data Lake und Data Warehouse) sowie Optionen für (fast) jeden zur Bearbeitung und Transformation von Daten (SQL-basierte Engines, Spark, ADX) kombiniert. Aber auch hier war die Verwaltung und vor allem die Gesamtpreisgestaltung nicht einfach zu beurteilen. Jeder Teil von Azure Synapse Analytics wurde einzeln abgerechnet und jede Compute Engine verwendete ein anderes Format für die Datenspeicherung. Spark konnte Data Lake Storage und/oder dedizierte SQL Pools nutzen, Data Explorer verwendet das Data Explorer-Datenbankformat und SQL-Engines nutzen ihr eigenes Speichermodell.
Wie könnte eine ideale Analytics Lösung aussehen...
- Wie wäre es, wenn Sie eine Analyselösung starten könnten, ohne sich über die Kosten der verschiedenen Komponenten Gedanken zu machen (abgesehen von Rechenleistung und Speicher)?
- Wie wäre es, wenn Sie sich in einem einzigen Portal anmelden und an all Ihren Datenaufgaben arbeiten könnten, ohne die Tools wechseln zu müssen?
- Was wäre, wenn Sie Ihr Wissen über die aktuellen Azure-Datendienste wie Azure Data Factory, SQL Serverless, SQL Dedicated Pools, Spark und Azure Data Lake wiederverwenden könnten, ohne „noch ein weiteres Analysetool“ erlernen zu müssen?
- Was wäre, wenn Ihnen diese analytische Lösung als Software-as-a-Service-Produkt zur Verfügung gestellt wird, bei dem Sie sich nicht um die Instanziierung von Analytics-Laufzeiten kümmern oder an die Bereitstellung von Speicherdiensten denken müssen?
- In der Vergangenheit wurden selbst innerhalb einer integrierten Analyselösung Daten von einem Ort zum anderen kopiert. Denken Sie an einen Data Lake als Archivierungs-/Staging-Schicht, einen SQL Dedicated Pool als Data Warehouse und Power BI als semantische und die Berichtsschicht. Zwischen jeder dieser Stufen wurden Daten dupliziert.
- Einer der Gründe, warum die Daten zwischen den verschiedenen Rechen- und Analyse-Engines dupliziert wurden, lag in den unterschiedlichen (internen) Speicherformaten. Wie wäre es, wenn eine Analyselösung ein einziges Format für alle verschiedenen analytischen Workloads hätte? Und stellen Sie sich eine Welt vor, in der die Ergebnisse der Engine Nr. 1 direkt von der Engine Nr. 2 oder Nr. 3 abgerufen und verwendet werden könnten.
- Und nicht zuletzt, was wäre, wenn eine Analyselösung Ihnen durchgängige Sicherheit, Datenverfolgung und Compliance unter einem einzigen Dach bieten würde?
Die Zukunft von Microsoft Analytics ist da - Einführung von Microsoft Fabric!
Angekündigt auf der MS Build 2023 (Link zum Blogpost), hebt Microsoft Fabric den Microsoft Analytics Stack und die Produkte auf die nächste Stufe.
Bisher ausgehend von einer Menge verschiedener Tools zum Aufbau Ihrer Lösungen, bringt Fabric sie alle unter ein einziges Dach. Die übergeordnete Idee und der Zweck ist es, "End-to-End-Analysen vom Data Lake bis zum Business User" bereitzustellen.
Lassen Sie uns ein wenig tiefer in die Grundpfeiler von Microsofts Fabric eintauchen.
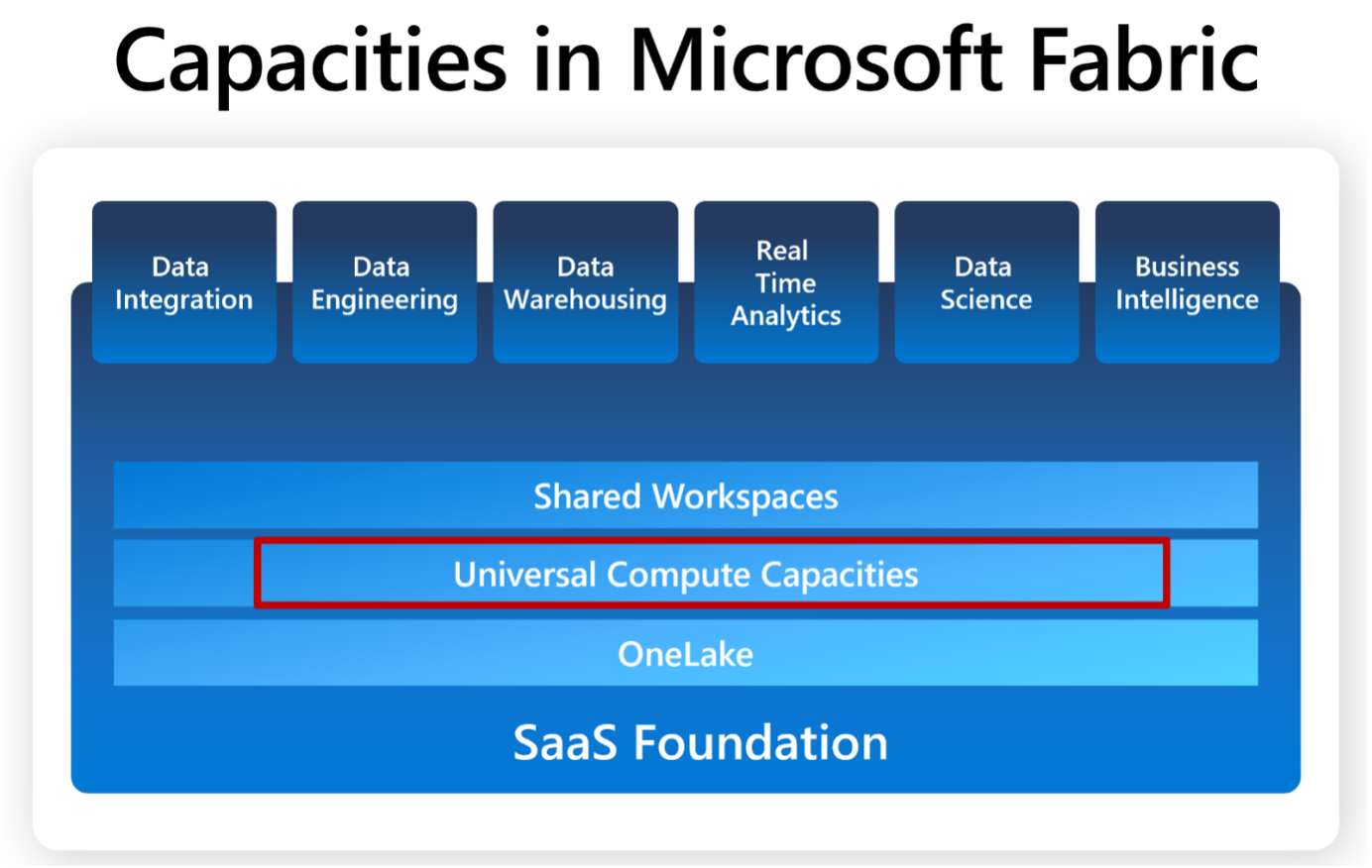
- Datenspeicherung - OneLake, um alle Ihre Informationen an einem Ort zu speichern und - standardmäßig - ein offenes Standard-Speicherformat zu verwenden.
- Compute-Workloads für verschiedene Rollen, um an jedem Aspekt der Analyse zu arbeiten - von Datenintegration, Data Engineering, maschinellem Lernen bis hin zur Berichterstellung.
- Strukturieren Sie Ihre Daten in Arbeitsbereiche und nutzen Sie diese Daten in Ihrem Unternehmen gemeinsam.
- Wiederverwendung bereits bekannter und etablierter Microsoft-Datendienste, ohne dass neue Tools erlernt werden müssen, und deren Integration in eine einzige Software-as-a-Service-Analyseplattform.
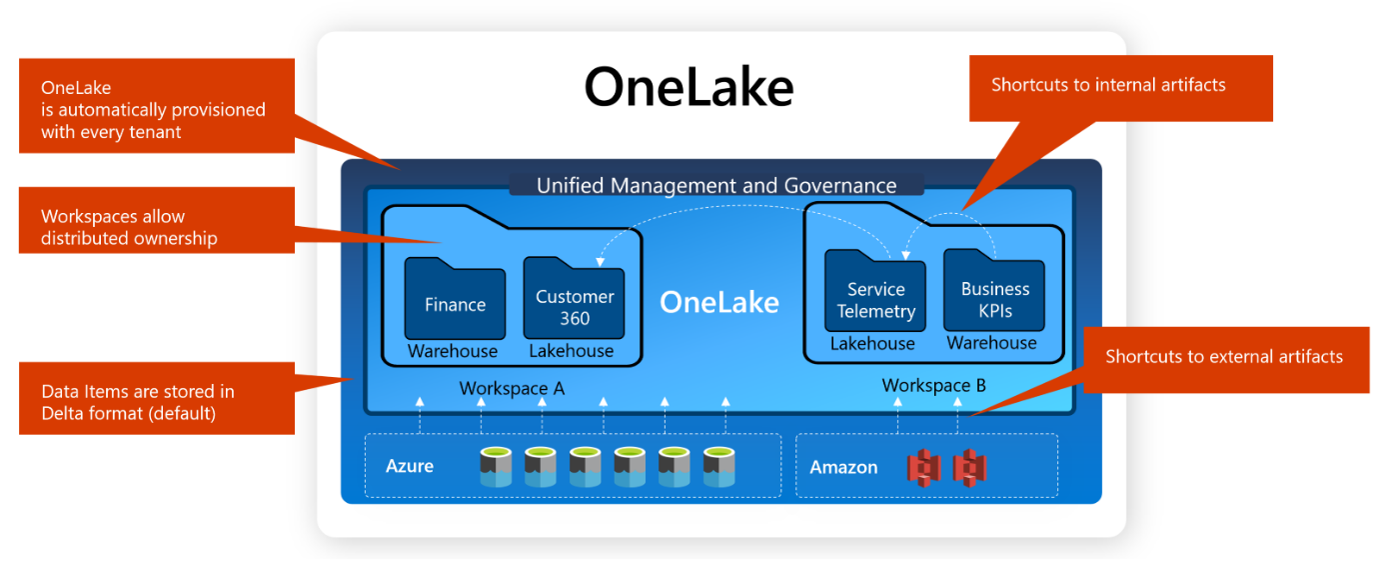
Datenspeicherung in Fabric - OneLake
OneLake ist DER Speicherort in Fabric. Mit dem SaaS-Ansatz ist OneLake ein einziger, einheitlicher logischer Data Lake für Ihr gesamtes Unternehmen. Sie müssen sich nicht um die Instanziierung und Konfiguration von Speicherkonten kümmern - das wird im Hintergrund für Sie erledigt. Selbst wenn Ihr Unternehmen über den ganzen Globus verteilt ist, hilft OneLake in diesem Fall und stellt Speicherkonten in verschiedenen Regionen der Welt zur Verfügung. Über diese technischen Details hinaus kombiniert OneLake die Daten in einem einzigen logischen Data Lake.
Die Daten in OneLake werden im offenen Standard-Delta-Format (Parquet-Files plus Transaktionsprotokolle) gespeichert, so dass jedes Tool, welches das Delta-Format lesen und schreiben kann, die Daten innerhalb von Fabric nutzen kann. Nicht nur die auf dem Data Lake basierenden Workloads speichern ihre Daten im Delta-Format, auch Data Warehousing und sogar Power BI interagieren direkt mit den Delta-basierten Daten in OneLake.
OneLake basiert auf der Azure Data Lake Storage Gen2-Technologie, so dass alle bereits vorhandenen API-Aufrufe und Tools auch mit OneLake funktionieren.
Workspaces sind die Konzepte zur Strukturierung Ihres OneLake - jedem Workspace ist eine Fabric-Kapazität zugewiesen und - ab sofort - die Ebene der Definition von Sicherheit und Zugriff zugeordnet.
Workspaces selbst sind keine geschlossenen Datensilos. Mit Hilfe von Shortcuts können Sie - wie symbolische Links in Ihren Dateisystemen - Verbindungen zu anderen Daten in OneLake selbst herstellen. Dies macht den Weg frei für eine einzige Kopie der Daten und keine Duplizierung von Daten in Ihrer Analyselösung. Shortcuts können sogar auf andere Dienste außerhalb von Microsofts Datenuniversum ausgedehnt werden, wie z.B. Amazon Storages.
Workloads in Microsoft Fabric
Ausgehend von dem einen Ort, an dem Ihre Daten in Ihrem Unternehmen (nicht nur logisch) gespeichert werden - dem OneLake - gibt es verschiedene Aufgaben, die mit Ihren Daten erledigt werden müssen.
Zunächst müssen Sie
- Ihre Daten integrieren und sammeln,
- Ihre Daten umwandeln und bearbeiten ("Ihre Daten massieren", wie es die „Guys in a Cube“ so gerne nennen 😉 )
- und dann vielleicht ein Data Warehouse auf Ihren Daten aufbauen
- und manchmal lernen Sie mehr über Ihre Daten, wenn Sie Data Science einsetzen.
In manchen Projekten fließen Ihre Daten in Echtzeit und müssen auch in Echtzeit analysiert werden.
Außerdem ist jeder Datenpool ohne ein angemessenes Reporting und Business Intelligence nicht vollständig.
In Fabric basieren all diese verschiedenen Workloads auf OneLake-Daten. Es gibt keine unterschiedlichen Wege, Daten zu organisieren, keine Notwendigkeit, Daten von einem zum anderen System zu übertragen. Jeder Workload kann direkt die Ausgabe eines anderen Workloads lesen.

Also, welche Workloads gibt es nun in Microsoft Fabric?
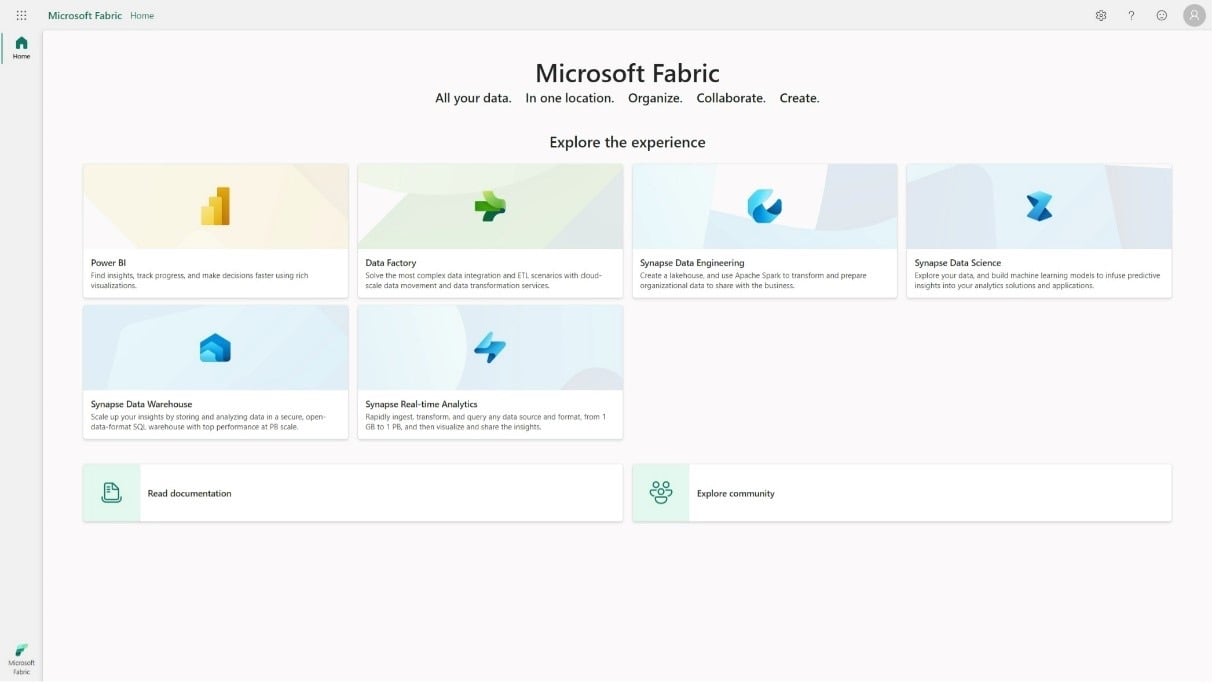
- Data Integration basiert auf der bekannten Azure Data Factory-Technologie und den Data Flows, die Sie vielleicht von Power Query online kennen. Beide Wege sind dazu da, Daten zu lesen, zu transformieren und in den Fabric OneLake (Workspace) zu bringen.
- Data Engineering basiert auf der gleichen Spark-Engine und -Technologie, mit der Sie bereits vertraut sind. Eines der Hauptkonzepte von Fabric ist der Aufbau eines Lakehouse für alle Ihre Unternehmensdaten. Und diese Daten in Ihrem Lakehouse sind nicht versteckt und nur auf Spark beschränkt. Dank OneLake und dem Delta-Format, das von allen Workloads verwendet wird, können die transformierten Datentabellen von allen anderen Workloads genutzt werden. Sogar standardmäßig werden die generierten Delta-Tabellen in OneLake erkannt und registriert, um ein integriertes File-to-Table-Erlebnis zu bieten.
- Data Warehousing: SQL Dedicated Pools waren der Anfang, Data Warehousing in Fabric können Sie sich als „SQL Pools on fire“ vorstellen. Im Hintergrund verwenden Sie Delta/Parquet-Tabellen als Speicherformat und eine serverlose Engine mit automatischer Skalierung, um die Rechenarbeit zu erledigen. Mit T-SQL können Sie Ihre Daten verarbeiten – so wie Sie es bereits gewohnt sind.
- Data Science: Spark, MLFlow, Cognitive Services und Notebooks sind bereits Ihre Freunde?
Gut - denn auch in Fabric werden diese Technologien weiter existieren und die Grundlage für Ihre Data Science-Arbeit bilden. Erwarten Sie eine tiefe Integration (aufgrund von OneLake und dem gesamten Fabric-Dach), aber auch einige aufregende Erweiterungen für eine bessere und produktivere Art, Data Science zu betreiben.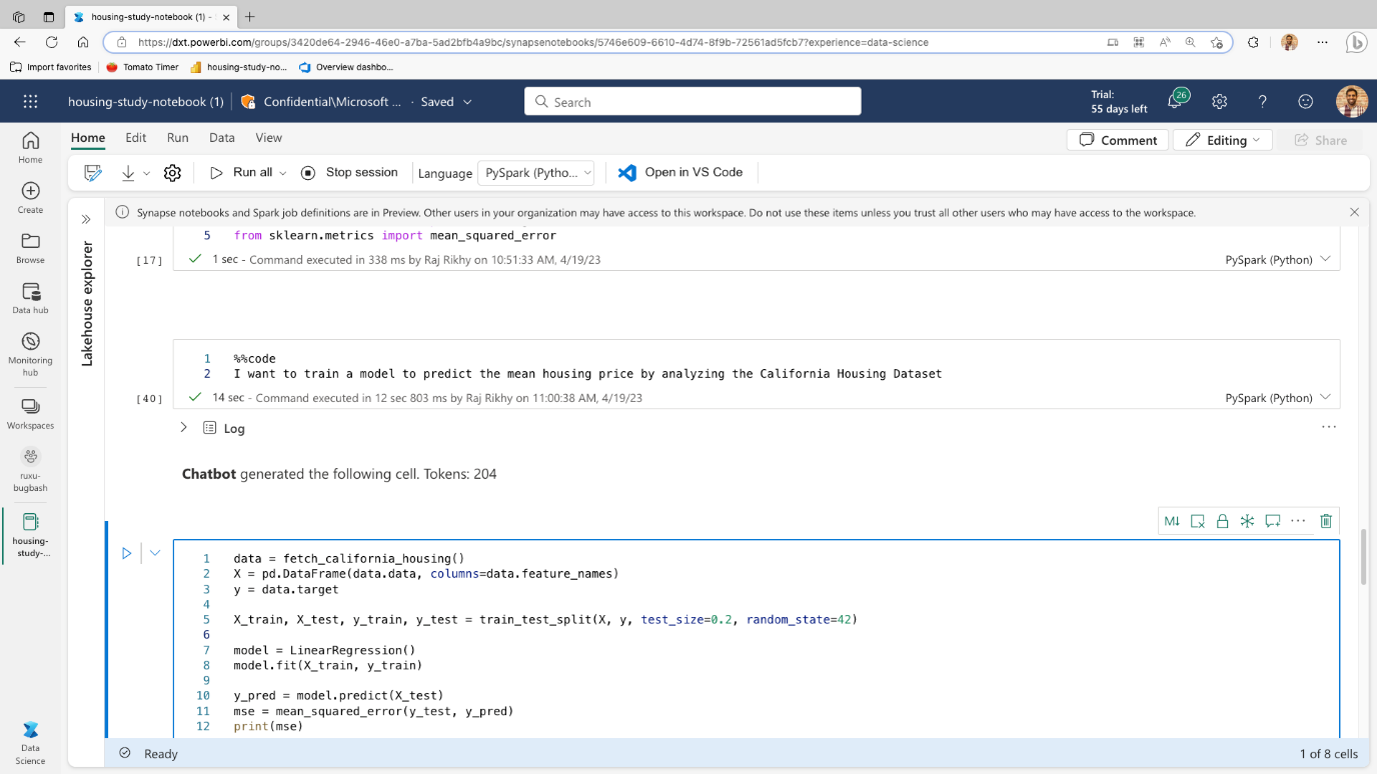
- Real Time Analytics: Echtzeitanalysen sind in vielen Szenarien in der Unternehmenswelt wichtig geworden, z.B. Log Analytics, Cyber Security, Predictive Maintenance, Lieferkettenoptimierung, Customer Experience, Energiemanagement, Bestandsmanagement, Qualitätskontrolle, Umweltüberwachung, Flottenmanagement und Sicherheit. Der Teil der Streaming-Echtzeitdaten wird von der bisher bekannten Azure Data Explorer (ADX/Kusto) Technologie übernommen. Diesmal jedoch direkt integriert und basierend auf demselben Speicherformat (Delta/Parquet). Daten in Ihrem Echtzeitkontext werden automatisch in Ihr zentrales Lakehouse gespiegelt - eine Datenkopie ist hier nicht notwendig.
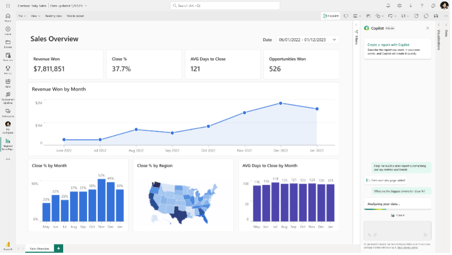
- Business Intelligence: In Fabric wird standardmäßig eine semantische Schicht (auch bekannt als Power BI-Dataset) in Ihrem Lakehouse erzeugt. Ja - standardmäßig und automatisch! Außerdem verwendet dieses Dataset nicht den Import- oder DirectQuery mode, sondern einen neuen Verbindungsmodus - den Power BI Direct Lake mode.
- Direct Lake mode: Durch die Verwendung dieses Verbindungsmodus werden die besten Eigenschaften von Import und DirectQuery mode kombiniert - schnelle Datensatzleistung und aktuelle Informationen. Im Direct Lake mode liest Power BI die Daten direkt aus OneLake, wenn dieser Teil des Datensatzes angefordert wird. Um die Daten aus OneLake schnell zurückzuliefern, sind diese Delta-Tabellen optimiert (VOrder), aber immer noch 100% kompatibel mit dem offenen Standard-Delta-Format (und können somit von allen anderen Anwendungen genutzt werden).
- Direct Lake mode: Durch die Verwendung dieses Verbindungsmodus werden die besten Eigenschaften von Import und DirectQuery mode kombiniert - schnelle Datensatzleistung und aktuelle Informationen. Im Direct Lake mode liest Power BI die Daten direkt aus OneLake, wenn dieser Teil des Datensatzes angefordert wird. Um die Daten aus OneLake schnell zurückzuliefern, sind diese Delta-Tabellen optimiert (VOrder), aber immer noch 100% kompatibel mit dem offenen Standard-Delta-Format (und können somit von allen anderen Anwendungen genutzt werden).
Kein Workload ohne Fabric Capacity...
Da Microsoft Fabric ein SaaS-Produkt ist, müssen Sie die verschiedenen Workload-Komponenten wie bisher instanziieren und verwalten - zum Beispiel in Azure Synapse oder in einer "einfachen" Datenlösung auf der Basis von Azure-Diensten.
Ein Workspace in Fabric benötigt eine Kapazitätszuweisung, da in dieser Umgebung Storage und Compute getrennt sind. Daher ist ohne eine zugewiesene Kapazität keine Datentransformation, Analyse, Warehousing möglich.
Soweit ich weiß, wird es Kapazitäten in verschiedenen Leistungsstufen geben, die auf Abonnementbasis verfügbar sein werden.
Um es zusammenzufassen...
Ich denke, wir brauchen alle etwas mehr Zeit, um diese Ankündigungen und die Optionen, die der neue Microsoft Fabric-Stack mit sich bringt, zu verdauen.
Mit der auf der Build angekündigten Public Preview erhalten wir alle die Chance, Microsoft Fabric auf unseren eigenen Workloads auszuprobieren (siehe https://aka.ms/try-fabric), zu lernen, wie man damit interagiert und vor allem Lösungen auf der Grundlage von Best Practices entwickelt. Denken Sie daran, dass es sich um eine erste öffentliche Preview-Version handelt, und rechnen Sie daher mit einigen Problemen, Lernkurven und vielleicht einigen (kleinen) Rückschritten, aber mit unserem gemeinsamen Feedback können wir die Analytics-Plattform der Zukunft gestalten.
Ich bin mehr als begeistert von den neuen Möglichkeiten und freue mich darauf, in naher Zukunft einige Projekte auf der Basis von Fabric zu starten.
Weiterführende Links:
- Erfahren Sie mehr über Microsoft Fabric: https://aka.ms/try-fabric
- Webinar-Reihe: https://aka.ms/fabric-webinar-series
- Microsoft Fabric Blog Seite: https://aka.ms/fabric-tech-blog
- E-Book zu den ersten Schritten: https://aka.ms/Getting-Started-eBook
Share this

Daumen mal PI - echt jetzt? Wie moderne Analyticslösungen das Bauchgefühl ablösen

Microsoft Fabric Update von der FabCon 2025: Neuerungen in KI-Integration, Sicherheit und Benutzerfreundlichkeit
